
近期,合肥大学人工智能与大数据学院大模型与自然语言处理团队在大语言模型对齐机制与参数高效微调方向取得重要研究进展。相关研究成果被自然语言处理领域顶级国际会议ACL 2026 Main Conference(CCF A类)正式录用。该论文由赵清华博士担任第一作者,2024级硕士生龚雪玲、陈馨雨为学生作者,李新路教授担任通讯作者,合肥大学人工智能与大数据学院为第一完成单位。
研究背景:监督微调的层间贡献差异与均匀更新策略的局限性
监督微调(Supervised Fine-Tuning,SFT)是将大语言模型从博览群书转变为善于表达的关键步骤——研究表明,仅需约1,000条精心标注的样本,便足以让基础模型蜕变为流畅的指令跟随助手。然而,微调的代价不容忽视:它可能导致模型遗忘原有知识,即所谓的灾难性遗忘,甚至悄然破坏预训练阶段构建的安全护栏。
更关键的问题在于,现有主流参数高效微调方法(如LoRA)普遍对模型所有层施以均匀更新,隐含地假设每一层对指令对齐的贡献相同。但这一假设从未被系统验证:微调究竟在哪里发生?哪些层真正决定了对齐的成败?
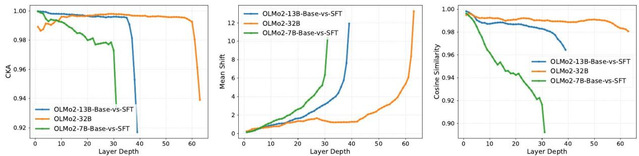
图注:Base模型与SFT模型在各层的表示差异(CKA、余弦相似度与均值偏移)。中间层表示高度稳定,而最终若干层发生急剧偏移,揭示了监督微调对模型表示的影响并非均匀分布于各层,而是高度集中在最终若干层——浅层和中间层的表示结构在微调前后几乎保持不变,而顶层发生了根本性的重组。
创新成果:揭示对齐的架构局部性并提出高效微调新方法
为解答上述问题,研究团队对Mistral-7B及OLMo2系列(1B至32B参数规模)展开了系统性的逐层分析,构建了一套涵盖三类维度的综合分析框架,首次从信息论、几何与优化角度系统揭示了监督微调的内部运作机制。
研究的核心设计与发现可概括为三个层次:
1. 三类指标的综合分析框架:信息论维度采用矩阵熵、有效秩与表示稀疏度,追踪各层信息容量与特征维度的变化;几何维度引入中心化核对齐(CKA)和余弦相似度,衡量基础模型与微调模型在同一层表示空间的结构差异;优化维度直接测量各层参数更新的Frobenius范数,量化不同深度所承受的优化压力。
2. 深度依赖适应规律的系统揭示:实验在多个模型规模与评测基准上呈现高度一致的规律——基础模型与SFT模型的表示相似性在浅层至中间层保持高度稳定(CKA维持在0.98以上),而在最后若干层发生急剧下跌;逐层探针实验揭示了鲜明的休眠-涌现相变,任务能力在最后约20%的层骤然涌现;层块互换实验进一步以因果方式确认,中间层是有效对齐的核心载体,而非均匀分布于全层。
3. Mid-Block Efficient Tuning方法:基于上述发现,论文提出将LoRA的可训练参数集中配置于模型中间段(约20%~80%深度区间),在保持参数量相当的前提下,将优化资源精准聚焦于对齐真正发生的层级区域,而非延续全层均匀分布的惯例
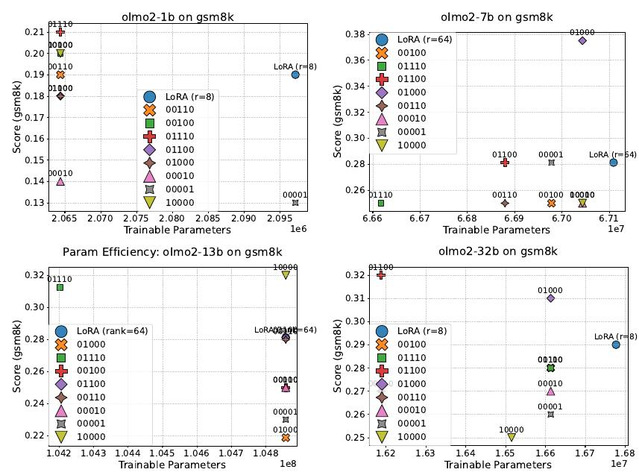
图注:OLMo2-7B在GSM8K上各分段配置的参数效率对比。Mid-Block Efficient Tuning方法将LoRA参数集中配置于中间层段,在参数量相当的条件下显著超越全层均匀更新策略,验证了有效对齐的架构局部性。
实验成效与学术价值
实验部分,论文在Mistral-7B及OLMo2(1B、7B、13B、32B)共五个模型上,覆盖GSM8K、MMLU、IFEval、WikiText、HumanEval、MT-Bench与ToxiGen七个评测基准进行了系统验证。结果表明,深度依赖的对齐规律具有跨模型规模与跨任务的普遍性。
具体来看,在数学推理任务GSM8K上,Mid-Block Efficient Tuning相较于标准全层 LoRA基线最高可带来10.7%的准确率提升(OLMo2-7B:37.5% vs. 28%);在OLMo2-13B 上可获得11.1%的提升;在OLMo2-32B上可获得10.3%的提升。最优中间段配置与最差边缘段配置之间的性能差距超过总分的20%,从实验层面有力确认了有效对齐的架构局部性。
论文还指出,Mid-Block Efficient Tuning可以方便地与现有参数高效微调框架集成,既保持工程上的轻量优势,又有效提升模型指令跟随能力。这意味着,在算力受限的真实部署场景中,研究人员有望以更低成本实现更优质的大语言模型对齐。
结语与展望
从研究意义上看,本工作重新审视了参数高效微调与指令对齐机制之间的关系,为大语言模型的对齐训练提供了一条兼顾效率与精度的新路径。相比单纯依赖更大数据量、更多参数或更复杂训练策略的方案,这种基于层间功能差异的设计思路更为精准,也更易迁移至不同模型与微调框架。
未来,围绕最优中间段的自适应识别、提示学习与层级选择的结合,以及向混合专家(MoE)等复杂架构的拓展,这一研究方向仍有广阔空间。对于需要在有限算力条件下高质量对齐大语言模型的推荐、教育、医疗与智能助手等场景而言,本工作提供了具有启发性的技术路线。
论文题目:A Layer-wise Analysis of Supervised Fine-Tuning
代码链接:https://anonymous.4open.science/r/base_sft
(人工智能与大数据学院 撰稿:龚雪玲 初审:嵇圣硙 复审:吴志泽 终审:胡萍)